원래는 SQL 문제만 쭉 풀다가 요즘은 리트코드에서 판다스 버전으로 문제를 풀고 있습니다.
현재 Leet-Code 판다스 버전을 20문제 정도 푼 상태인데 그 중에서 인상 깊었던 문제들을 정리해 공유해보려고 합니다.
혼자서 작성했을 때 코드가 꽤나 길었지만 다른 사람들 풀이를 참조하다보니 코드가 확 간결해져서 인상깊었던 문제들의 풀이과정을 정리해봤습니다.
1. 방문은 했지만 거래는 안한 고객 수 찾기

두 테이블을 합치고 빼고 하려고 하다보면 코드가 길어질 수 있지만 '~' 을 활용하고 [ ] 안에 필터링을 활용하면 훨씬 간결해지는 것을 볼 수가 있습니다.
~에 있는 지를 확인하는 .isin(), Null 값도 Count 에 포함하는 .size(), 열 이름을 설정하면서 동시에 Dataframe 으로 전환해주는 .reset_index() 도 사용했습니다.
2. 기계 별 작동 시간 평균
machine_id, process_id / activity_type 별로 timestamp 를 분류해서 볼 필요가 있는데 이 때 pivot_table 을 사용하니 코드가 간결해졌습니다. 인덱스를 열로 바꿔서 보이게 하려면 .reset_index 를 해줘야 합니다.
machine_id 를 기준으로 시작, 끝의 차이의 평균을 구하려고 하므로 groupby 이후 apply 를 활용하니 코드를 한번에 작성할 수 있었습니다.
3. 평균 판매 가격
구매 가격이 start_date, end_date 사이에 위치하도록 해야 한다는 것이 문제의 핵심입니다.
이를 해결하기 위해 prices, units_sold 테이블을 일단 합친 후, 구매 가격이 판매 시점에 놓이도록 하고 동시에 판매되지 않은 물품은 null 값으로 같이 포함시켰습니다.
다음으로, 평균을 구해야 하는데, 일단 product_id 별로 그룹화한 후에, price 와 units 을 곱한 것의 합을 units 의 합으로 나누도록 전체적으로 apply 를 적용하고 판매되지 않은 물품은 0으로 처리하였습니다.
4. 품질과 불량 비율
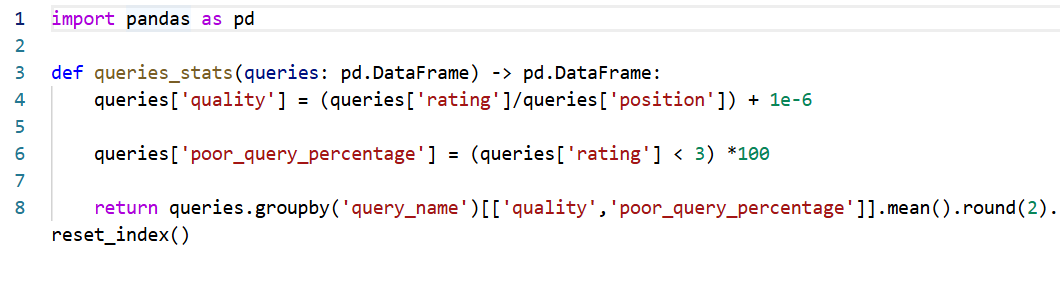
문제에서 품질은 rating/position 의 평균, 불량 비율은 rating 이 3보다 낮은 것의 백분율로 정의되어 있습니다.
이 문제에서 백분율의 경우 (queries['rating']<3) 과 같이 True 일 경우 1을 반환하는 Boolean *100 과 그것의 평균을 구하면 쉽게 구할 수 있으므로, groupby, mean 을 활용하면 품질과 불량 비율을 한번에 구할 수 있게 됩니다.
품질 부분의 1e-6 은 문제 상 오류를 방지하기 위해 더해주었습니다.
'데이터 사이언스 기초' 카테고리의 다른 글
| 웹 스크래핑의 기본 (0) | 2024.11.13 |
|---|---|
| 파이썬 기초 프로젝트 리뷰 (3) | 2024.11.09 |
| SQL Window Function (0) | 2024.11.04 |
| 시계열 분석 (0) | 2024.11.02 |
| 거리 측도 (0) | 2024.10.31 |