1, 데이터 분석트랙에 참여하게 된 히스토리
저는 고려대학교 정치외교학과 졸업생으로, 정치 현상을 분석하는 과정에서 데이터의 중요성을 실감하게 되어 데이터 분석에 관심을 가지게 되었습니다.
2024년 1월부터 주로 Coursera 플랫폼으로 다음의 강의들을 들으며 공부했습니다.
1. 통계, 수학
Introduction to Statistics(Stanford University)
Mathematics for Machine Learning(Imperial College London)
Introduction to Probability (Harvard, Stats 110, Joe Blitzstein, Youtube)
Machine Learning (Stanford, CS229,Andrew Ng, Youtube)
2. 프로그래밍
Python for Everybody Specialization(University of Michigan)
Introduction to Data Science in Python (University of Michigan)
Applied Plotting, Charting & Data Representation in Python (University of Michigan)
Applied Machine Learning in Python (University of Michigan)
Supervised Machine Learning : Regression and Classification (Andrew Ng)
Advanced Learning Algorithms (Andrew Ng)
Text Retrieval and Search Engines (University of Illinois Urbana-Champaign, ChengXiang Zhai)
Text Mining and Analytics (University of Illinois Urbana-Champaign, ChengXiang Zhai)
이를 바탕으로 두 가지 프로그램을 제작했습니다.
첫번째는 발표 자료 사례 도출 프로그램입니다. 2024년 1학기 정치가론 수업 과정에서 청년 정치의 활성화 방안에 대한 발표 과제가 있었는데 발표자들의 발표 자료 별로 관련 사례를 도출하는 프로그램을 제작하였습니다.
* 기법: Okapi BM25, LDA Model
* 방법: 역대 국회의원 정보 파일에서 국회의원 당선 당시 청년(40세 이하)였던 국회의원 명단 추출 → 웹 스크래핑을 통해 위키피디아에서 청년 국회의원 정보 추출 → 발표 자료별로 lda 를 통해 토픽 5개씩 추출 → BM25 기반 검색 엔진에 토픽 5개를 입력하여 관련성이 가장 높은 순으로 청년 국회의원 4명까지 추출 → 발표 내용과 결과 사례를 비교하면서 BM25 의 변수 조정

두번째는 지지율 관련 키워드 추출 프로그램입니다. 사회과학적 분석과 글쓰기 수업에서 대통령 지지율에 영향을 미치는 요인을 분석하는 과정에서 데이터를 활용한 분석 작업을 직접 수행하였습니다. 지지율이 가장 크게 하락한 시기 동안의 신문 1면에 해당하는 기사들을 웹스크래핑을 통해 수집하였고, 해당 기간동안 Iterative Topic Modeling with Time Series Feedback (kim et al, 2013) 모형을 통하여 지지율과 관련된 키워드들을 수집하여 분석하였습니다.
* 기법: PLSA Model, LDA Model, prior model
(참고 문헌: Mining Causal Topics in Text Data: Iterative Topic Modeling with Time Series Feedback (Kim et al, 2013))
* 방법: 윤석열 대통령의 지지율의 증가 추이, 감소 추이 가운데 증감이 가장 큰 기간을 추출: (2022.6~9, 2024.3~5) → 웹스크래핑으로 정해진 기간 동안의 신문 1면 기사 추출 → 추출된 기사 중 중복 제거 → 기사 각각에 대하여 LDA 모델을 활용해 토픽 3개씩 추출 → 매 달의 토픽들의 모음에 대하여 각 달의 기사수 평균으로 토픽 수를 설정하여 PLSA 모델을 실행 → 지지율의 감소와 음의 상관관계를 가진 토픽과 단어들에 대하여만 granger test 의 유의확률에 기반하여 prior 을 생성하고, PLSA 모델 내부에서 Feedback을 3회 제공하여 토픽 도출 → 문맥을 기준으로 여러 주제에 대하여 범용적인 단어를 반복적으로 사전 배제

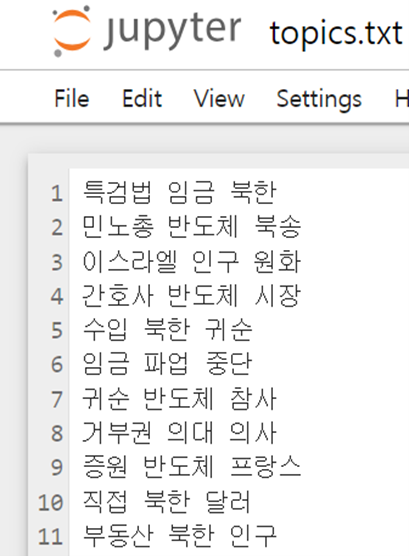
프로그램을 제작해보니, 직접적으로 관련이 없는 키워드들도 함께 수집된다는 점에서 분명한 한계가 있었습니다. 그렇지만 지지율에 기반한 기존 연구를 같이 활용하면 관련 있는 키워드들을 일부 추려낼 수 있었고 그에 기반하여 레포트를 제출하였습니다.
2. 본 코스 수료 후 성장하고 싶은 방향성
저는 자연어 처리 기술에 주된 관심을 가지고 있으며, 자연어 처리 기술을 비롯한 데이터 관련 프로그램들에 기반하여 의사결정을 지원하거나 정보 검색 시스템을 제작하는 데 일조하는 것을 목표로 하고 있습니다. 현재는 대학원 진학을 목표로 준비 중입니다.
3. 내일배움캠프에서 기대하는 것
프로젝트나 논문 작성 활동에 참여하여 실무적인 경험을 많이 쌓고 싶습니다.
'데이터 사이언스 기초' 카테고리의 다른 글
| 측정과 척도 (0) | 2024.10.10 |
|---|---|
| 표본 추출 방법 (1) | 2024.10.08 |
| 가설 검정 (1) | 2024.10.04 |
| 기술 통계 (0) | 2024.10.02 |
| 데이터, 데이터 사이언티스트란? (1) | 2024.09.30 |